Artur Niewiarowski from Krakow University of Technology was awarded the degree of Doctor of Science in the field of Engineering and Technical Sciences in the discipline of Information Technologies and Telecommunications.

PhD defense at IPPT PAN on December 4, 2024, with Prof. Janusz Szczepański (on the left)
The title of the dissertation is "Application of the Edit Distance Algorithm for Quantitative Analysis of Textual Data." The supervisor is Dr. hab. Eng. Marek Stanuszek, professor at the Cracow University of Technology.
The aim of this dissertation was to develop and implement a new, efficient method for analyzing the similarity of textual data, independent of lexical systems for most languages of European origin.
Text similarity analysis is one of the key challenges in natural language processing (NLP), with applications in areas such as plagiarism detection, stylometry, machine translation, and semantic analysis. Traditional methods for comparing texts often rely on complex lexical processes, such as reducing words to their base forms or analyzing semantic relationships between words. While these approaches are effective in many cases, they can be limited by the specificity of a given language, require access to advanced technologies or large datasets, and involve high computational demands.
The method proposed in this dissertation serves as a foundation for building efficient anti-plagiarism systems and stylometric algorithms, leveraging the full computational power of modern computers, both personal and industrial (including scientific). Lexical independence in this context means, for example, eliminating the need to implement processes such as reducing analyzed words to their base forms or creating common word groups to achieve satisfactory analytical results. Importantly, the developed method does not rely on the latest technologies, such as word2vec or GloVe, making it a more universal approach, accessible even to users without advanced computational infrastructure or access to large training datasets. This independence translates into the universality of the mechanism for analyzing documents written in various languages and significantly accelerates its performance by removing the need to implement the aforementioned processes. The method is efficient enough to be installed as software on computers with standard computational parameters. In recent years, many companies worldwide have implemented regulations prohibiting their employees from sending electronic documents to cloud computing platforms, effectively to third-party providers. This highlights the growing importance of methods like the one proposed in this dissertation.
The dissertation also compares texts in terms of similarity within the same language, as well as across related languages from the same linguistic families. The aim was to demonstrate the effectiveness of the mechanism, particularly its sensitivity and adaptability to various languages. The analyzed textual data were sourced from diverse origins, including popular online encyclopedias and content generated by artificial intelligence. Different language versions of the same articles were either the result of translations by language translators or generated by AI models like ChatGPT.
Numerous tests conducted as part of the research demonstrated that the proposed method enables precise identification of similarities between texts, both within the same language and across different languages from the same linguistic family. Additionally, the method can effectively identify abuses related to text generation by artificial intelligence systems such as ChatGPT (in its various versions). The tests showed that analyzing sets of essays on a specific topic allows for detecting patterns characteristic of automatically generated texts. This capability is particularly significant in the context of education and science, where originality is a key criterion for evaluation.
 |
 |
 |
|
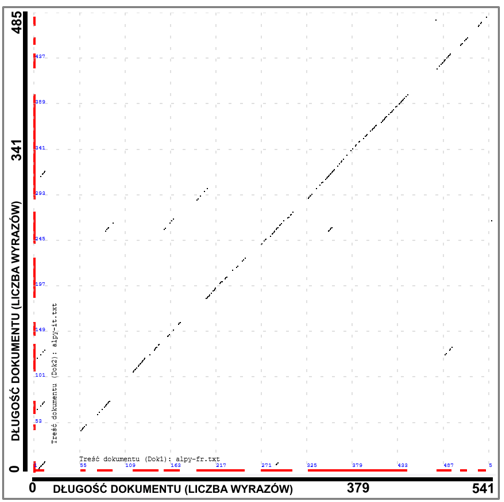
Graphical representation of the similarity between the same texts written in French and Italian |
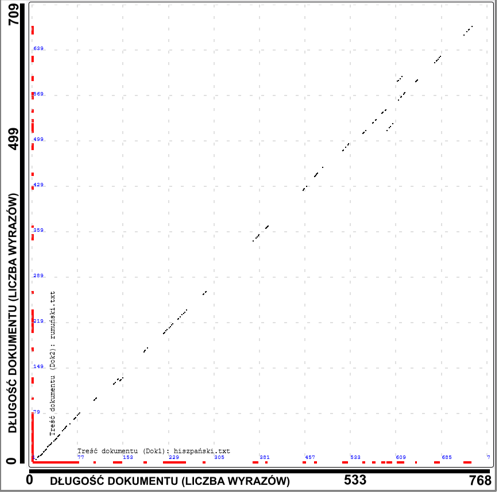
Graphical representation of the similarity between the same texts written in Spanish and Romanian |
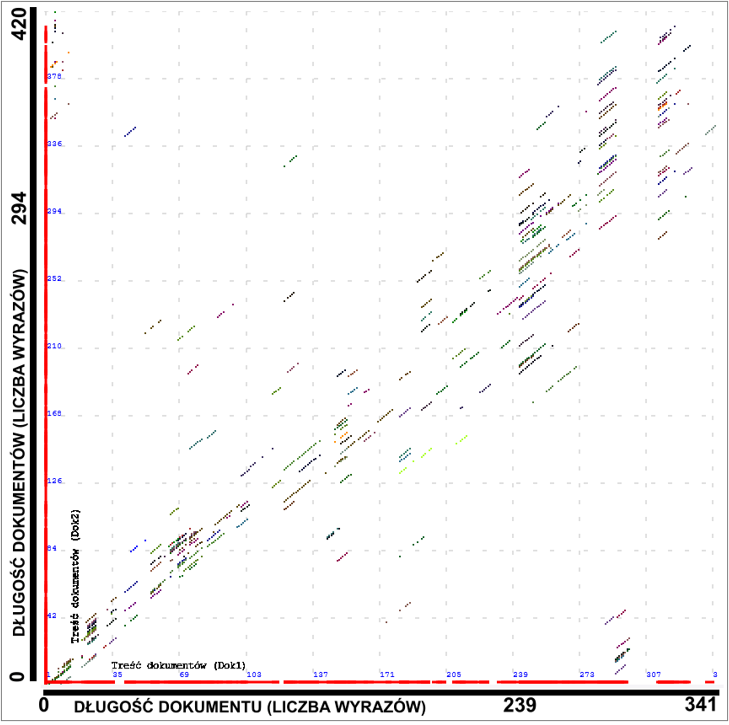
Graphical interpretation of the comparison between an essay written by ChatGPT 4o and forty texts generated by the same model on the same topic |